
Autore: Bruno Sfogliarini – Professore Data Analysis IULM Milano
Quando si parla di “modeling” nel Machine Learning si sta parlando dell’attività di “allenare un algoritmo di apprendimento automatico a prevedere delle categorie (o dei valori, insomma l’output) da delle variabili (categoriche o numeriche, insomma l’input), affinarlo a seconda delle esigenze del business e validarlo su dati di verifica (Towards Data Science)”.
Dal mio punto di vista, un modello è una rappresentazione semplificata della realtà che ne simula il funzionamento in un ambito specifico. Ad esempio, un modello regressivo di marketing mix è un’equazione che, sulla base dei valori delle variabili del marketing mix di un brand (le “cause”) restituisce una stima delle vendite o della quota di mercato (l’”effetto”).
Sempre secondo me, un modello deve essere “trasparente” cioè si devono “vedere” i suoi meccanismi interni altrimenti lo definisco una “black box”. In altre parole, per essere tale un modello deve essere ricostruibile da un altro modellista che abbia accesso agli stessi dati o più in generale alla stessa conoscenza di chi l’ha costruito per primo.
Questa mia visione di modelli e modellisti nasce quasi esattamente cinquant’anni fa…in quel giorno poco prima di Natale quando mio padre mi prese e mi portò in tram da MoVo a Porta Nuova. Già perché aveva deciso per il mio nono Natale di regalarmi una scatola di montaggio di un aeromodello, intendo di un modello volante un piccolo aliante da volo libero: il MoVo M 9 che vedete illustrato nella foto ripresa da un catalogo degli anni ’60.

Come si legge dalla descrizione dell’articolo nel catalogo, si tratta di un modello “di semplicissima costruzione”. Ecco, era talmente semplice costruirlo che io non riuscii mai a finirlo e tanto meno a vederlo volare, nonostante papà provò ad aiutarmi! Così da quel giorno sono ancora oggi preda della follia maniacale di ogni (aero)modellista, cioè di costruire l’n-simo modello e vederlo volare.
In verità, riuscii dopo una decina d’anni a realizzare per la prima volta quel sogno cioè a costruire un aliante da volo libero e vederlo volare come si deve, almeno per una sola volta. Sì, perché atterrò in un campo di granoturco maturo da cui non riuscì più, ahimè, a recuperarlo (!). Oggi più prosaicamente mi approvvigiono da artigiani modellisti dell’Est Europa e qualche volta ci vinco anche delle garette tra pazzi come me (vedi altra foto di qualche anno fa con me sorridente qui riportata).

Questa digressione personale e infantile prende il senso di connotare lo stato mentale del Data Scientist, che si muove seguendo due principi fondamentali:
- non saremo mai del tutto soddisfatti del nostro ultimo modello, anche se funzionerà perfettamente per il nostro utente
- l’unica vera ma fuggevole soddisfazione sarà quella di far morire d’invidia i nostri colleghi modellisti per il nostro ultimo modello
Anche le più elementari nozioni di dinamica ci portano a concludere che fondamentalmente i Data Scientist sono delle anime in pena. Penso che questa informazione sia rilevante per chi ci debba mai avere a che fare.
Più seriamente, il Modeling è la terza fase del processo TDSP, come ad esempio riportato da Microsoft in relazione alla propria piattaforma Azure Machine Learning. Gli obiettivi di questa fase sono:
- Preparare al meglio i dati per il modello di apprendimento automatico
- Creare un modello di apprendimento automatico che preveda la variabile obiettivo nel modo più accurato possibile
- Decidere se il modello possa essere messo in produzione
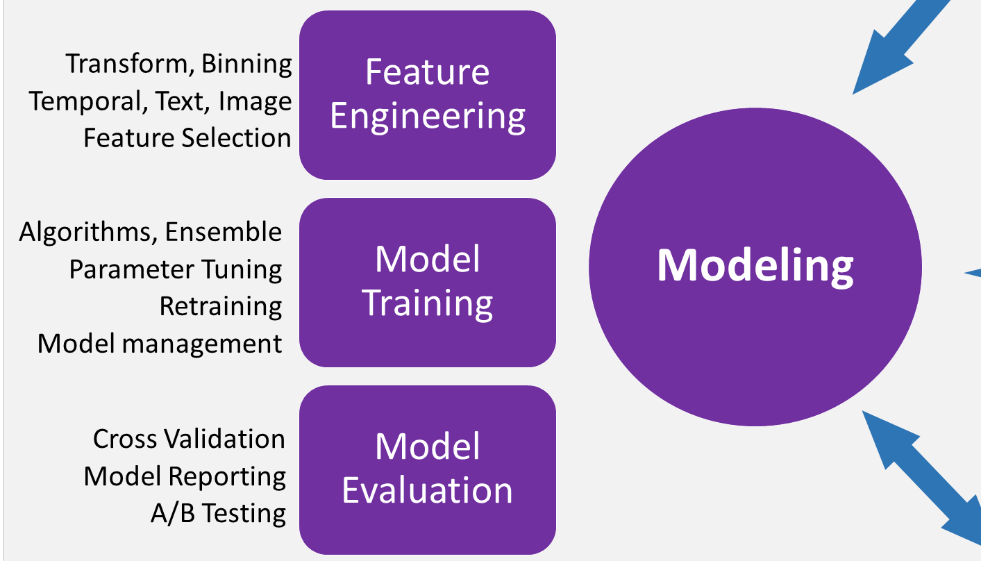
Nel Modeling sono affrontate tre attività principali:
- Progettazione delle variabili: sviluppare variabili evolute dai dati grezzi per facilitare il training del modello
- Training del modello: trovare il modello che risponda al problema nel modo più accurato possibile secondo un set definito di metriche di successo
- Determinare se il modello sia adatto per essere messo in produzione
In pratica la prima fase è quella più “artistica”, dove il modellista plasma i dati grezzi nelle variabili di input ad un modello ipotetico (perché ancora non realizzato) sulla base della propria esperienza e dell’intuizione creativa. La seconda fase è più “tecnica” e può essere anche facilitata da sistemi esperti o procedure semi-automatizzate. La terza fase consiste in un checkpoint, dove valutare se il modello funzioni abbastanza bene da distribuirlo in un sistema di produzione. Occorre porsi domande chiave quali:
- Il modello risponde al problema con sufficiente precisione sui dati di test?
- Bisogna provare qualche approccio alternativo? È consigliabile raccogliere dati aggiuntivi, eseguire altre operazioni di progettazione delle variabili di input o sperimentare altri algoritmi?
Il Modeling, inteso come fase del processo TDSP, produce tre risultati concreti:
- Set delle variabili: il codice per generare le variabili e la sua descrizione
- Report dei modelli: per ogni modello provato, un report standardizzato che consenta di confrontare i modelli tra loro
- Decisione del checkpoint: si può mettere in produzione il modello ottimale o no?
L’effettiva messa in produzione e distribuzione del modello sarà oggetto della fase successiva del processo, di cui parleremo più avanti e con meno enfasi ma spero uguale utilità.
P.S. Se qualcuno si chiederà quale sia il modello che uso attualmente, si chiama Simply-the-Best (non a caso…). Ormai ci volo da più di quindici anni e prende qualunque termica si formi sulla faccia della Terra. Quando mi capita involontariamente di vedere le espressioni dei soci del mio club dopo un mio voletto, mi si forma una specie di sorriso…
Commenti recenti