
Autore: Bruno Sfogliarini – Professore Data Analysis IULM Milano
Molti di voi, ma non tutti…, sono dei Baby Boomers cresciuti in città dove c’è o c’era una Rinascente. Chi rientra in questo target potrà rivivere appieno l’emozione di un bambino che viene accompagnato da un genitore a visitare il piano dei giocattoli della Rinascente la domenica. Mi dispiace per gli altri, che saranno tristi e che non sapranno mai cosa si prova! Forse, e dico forse, qualcosa di simile oggi può succedere alla prima visita di un Disney Store, dove però la varietà dell’assortimento è limitata per forza di cose.
Io l’ho provata quell’emozione almeno tre volte che mi ricordi, quelle domeniche pomeriggio quando papà mi ci portava e immancabilmente mi comprava un pacchetto di Pongo multicolore: una scatola di cartone con dentro sei bastoncini di plastilina colorata lunghi dieci centimetri scarsi per un paio di diametro, uno per colore base (giallo, blu, rosso), uno verde (!), uno nero e uno bianco. La sua scelta sempre uguale e la mia mancanza di capricci si comprendono meglio considerando che papà era un pittore e scultore…
Tornati a casa, mentre la mamma stirava, ci mettevamo al tavolo della cucina a lavorare la pasta di cera colle mani rendendola prima morbida e poi combinando i colori per ottenere altre tinte, come l’arancione o l’azzurro o il marrone… Finita la preparazione, papà mi modellava una casetta colorata su una base di terreno con il suo prato, l’albero, i fiori, il cancelletto…insomma una casetta di quelle delle illustrazioni delle fiabe o dei fumetti che leggevo.
Io partecipavo come potevo, ammirando le sue mani che davano forma e senso alla materia plasmandola sapientemente con ordine e maestria. Per finire, si faceva merenda con delle Crêpe Suzette alla marmellata di ciliegie sempre preparate da lui… Ora forse capite perché il mio ricordo è così dolce!

Per me i Big Data sono come il Pongo. Per qualcun altro saranno come i Lego, oppure come il Meccano, questione di gusti, ricordi, tempi e luoghi. In più sono anche vivi… In ogni caso i Big Data sono materia plasmabile, variegata, informe che ha valore solo perché alimenta la speranza di realizzare il sogno dell’automazione intelligente, cioè in altri termini l’obiettivo focale di ogni Data Scientist: la pigrizia assoluta.
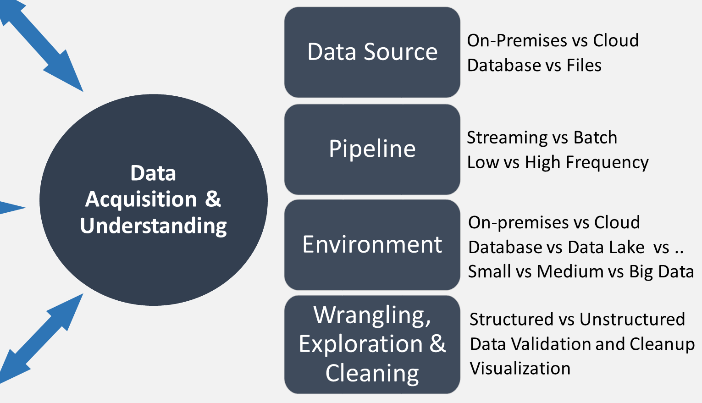
La prima cosa da fare avendo a disposizione dei Big Data utili per il nostro progetto di apprendimento automatico è la loro acquisizione e comprensione, appunto il secondo passo del processo TSPD come ad esempio descritto da Microsoft per la propria piattaforma Azure Machine Learning. Gli obiettivi di questa fase dell’analisi scientifica dei dati sono:
- Produrre un set di dati pulito e di alta qualità la cui relazione con le variabili obiettivo sia ben compresa, e collocarlo in un ambiente analitico adeguato in modo che sia pronto per la modellazione
- Sviluppare un’architettura di flusso (pipeline) per aggiornare regolarmente il set con dati nuovi e abilitare il processo di apprendimento automatico continuo
Dal punto di vista operativo, in questa fase sono affrontati tre compiti principali:
- Inserire i dati nell’ambiente analitico di destinazione, cioè costruire il processo per spostare i dati dalle fonti di origine alle strutture su cui eseguire le analisi, come ad esempio training e scoring
- Esplorare i dati per determinare se la loro qualità sia adeguata a rispondere agli obiettivi di business, cioè in pratica “pulire” i dati dall’inevitabile rumore presente in Big Data, comprenderne il valore informativo intrinseco (variabilità, rappresentatività, stabilità, …) e valutarne l’usabilità per spiegare le variabili obiettivo, scegliendo uno o più modelli predittivi
- Impostare un flusso di aggiornamento per i
nuovi dati, cioè sviluppare l’architettura della pipeline secondo tre
standard possibili:
- Batch-based
- Streaming o real time
- Hybrid
L’acquisizione e comprensione dati produce tre risultati:
Report sulla qualità dei dati: comprende misure riepilogative, relazioni tra ogni variabile di base ed obiettivo, classificazione delle variabili e altro ancora. Lo strumento IDEAR (Interactive Data Exploration, Analysis, and Reporting) facente parte di TDSP può generare questo report su qualsiasi set di dati tabellari, ad esempio un file CSV o una tabella relazionale.
Architettura della pipeline: l’architettura della soluzione può essere un diagramma o una descrizione del flusso dati di aggiornamento. Deve consentire sia lo scoring o previsione dei nuovi dati secondo il modello già stimato, sia la ristima dinamica del modello.
Checkpoint decisionale: prima di iniziare la progettazione completa delle funzionalità e la creazione di modelli, si introduce qui una possibilità di rivalutare il progetto in ragione del valore generabile previsto.
Si potrebbe:
- essere pronti a procedere
- dover raccogliere altri dati
- abbandonare il progetto perché non si dispone di dati adatti a rispondere alla domanda di business
Preparare i Big Data è come lavorare con la plastilina, solo che invece delle mani si usano dei software.
Se ora vi state chiedendo che fine faceva la casetta colorata di Pongo…beh dopo averla lasciata qualche giorno a prendere polvere la trasformavo in una palla di colore indefinibile, quello che il tagliente e cinico dialetto milanese chiama “colore del cane che scappa”. Voi, mi raccomando, non fate fare la stessa fine ai vostri Big Data e teneteli sempre vivi, brillanti e colorati!
Commenti recenti