
Autore: Bruno Sfogliarini – Professore Data Analysis IULM Milano
Quando ho iniziato a lavorare in azienda, più di trent’anni fa, c’erano le “librette” da seguire per portare a termine i processi produttivi che, nel mio caso, erano programmi in JCL che chiamavano delle sessioni di SAS sul mainframe. Per libretta quindi intendo la sequenza di passi da seguire per completare un’attività, e non invece l’altra libretta di cui a volte mi parlava mia nonna, cioè un quadernetto a quadretti dove il negoziante si annotava la spesa che la famiglia sosteneva a debito (e che doveva essere pagata, tutta o in parte, di volta in volta, al mese o appena la famiglia debitrice ne avesse avuto la possibilità). Il lavoro era sicuramente più facile all’epoca delle mie librette, mentre penso non sia cambiato molto dalle librette di mia nonna alle attuali carte di credito revolving…
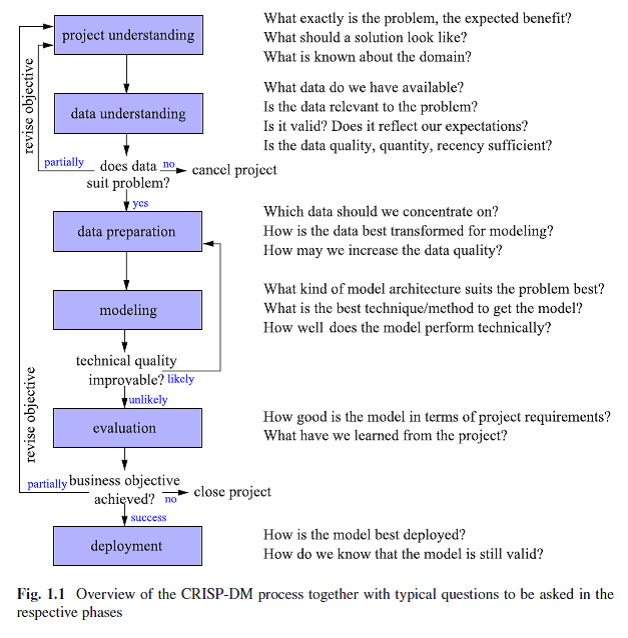
Ricordi a parte, il lavoro del Data Scientist può ancora essere agevolato da una sequenza ragionata e validata di passi che sia sufficientemente generale da adattarsi al problema da risolvere. La libretta della Data Science che esiste da più tempo è il metodo Cross-industry standard process for data mining (CRISP-DM). Si tratta di uno schema che prevede le seguenti sei fasi, che possono essere ripetute ciclicamente con l’obiettivo di revisionare e migliorare il modello analitico:
- Business (o Project) Understanding
- Data Understanding
- Data Preparation
- Modeling
- Evaluation
- Deployment
Nella figura a fianco, tratta da “Guide to Intelligent Data Analysis – How to Intelligently Make Sense of Real Data”, di Berthold et al edito da Springer, le diverse fasi del metodo sono accompagnate dalle domande chiave a cui si deve rispondere per poter procedere oltre.
L’obiettivo fondamentale del metodo è quello di rendere praticabile il data mining da chi non sia esperto,ma abbia forte conoscenza del business o del progetto.
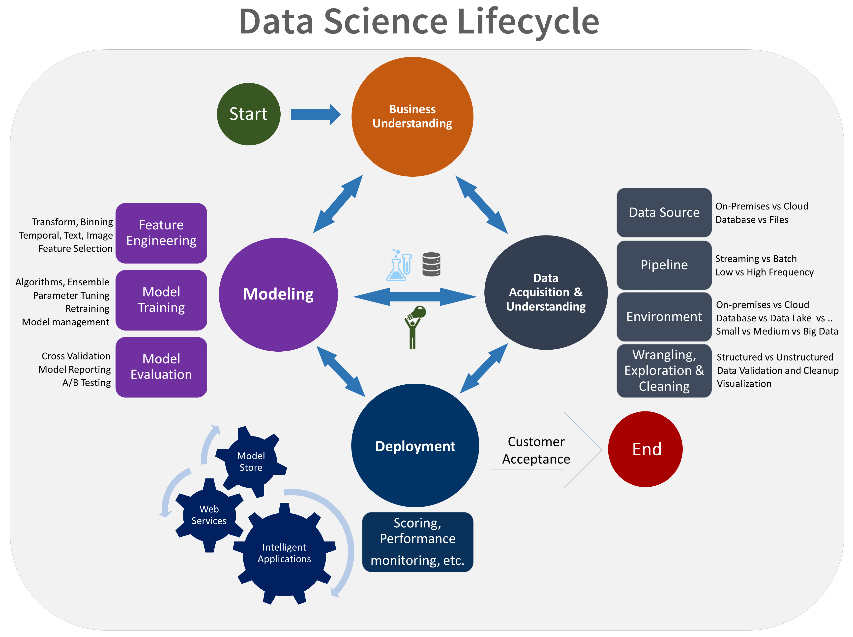
Una metodologia più recente per governare i processi di data science è il TDSP, Team Data Science Process, orientato appunto al lavoro in squadra su progetti che sviluppino applicazioni di intelligenza artificiale, come ad esempio modelli di machine learning per l’analisi predittiva. Il solo fatto di poter comunicare le attività al team e ai clienti usando termini standard consente di evitare grossi malintesi. L’uso di un approccio di questo tipo aumenta la probabilità di completare correttamente un progetto di data science complesso.
Al di là che si stia utilizzando il CRISP-DM o il TDSP, seguire una “libretta” vuol dire disporre di un riferimento puntuale e comprovato che faccia da guida passo per passo all’analista nell’esecuzione del progetto, partendo dalla comprensione degli obiettivi da cui è scaturito fino alla valutazione del beneficio che avrà generato. Per renderne più facile l’utilizzo, oggi la libretta è passata dalla forma cartacea a quella digitale e in pratica è integrata all’interno delle piattaforme di sviluppo di applicazioni intelligenti come ad esempio Microsoft Azure.
Anche la libretta del negozio di alimentari sotto casa si è trasformata nel tempo…infatti oggi possiamo verificare in tempo reale il saldo delle spese da pagare nell’area riservata sul portale titolari della carta di credito…ma forse era meglio quando i nostri debiti rimanevano nascosti tra le pagine del quadernetto nero custodito sotto al bancone!
Commenti recenti